Ph.D. student scholarship recipient Sangwoo Kim (at center) with faculty mentors Anuj Karpatne (at left) and Venkat Sridhar. Photo by Tonia Moxley for Virginia Tech.
The initiative builds upon a consistent collaboration between the two centers that began with the inauguration of CAIA in 2021. Faculty from the two centers have been working on joint research projects that includes a National Science Foundation-sponsored Convergence Accelerator project and some faculty are members of both centers.
Virginia Tech has received funding from the National Science Foundation for a collaborative research project that brings machine learning and data science research to the domain of Stable Isotope Ratio Analysis (SIRA) to improve discovery and traceability of illicitly-sourced timber products. Illegal timber trade (ITT) is the most profitable natural-resource crime, valued at 50-152 billion U.S. dollars per year.
“To enforce timber regulations and international frameworks, there is a need for accurate, cost-effective, and high-throughput tools that can be used to identify and trace illegally sourced timber products,” Ramakrishnan said.
The team brings together data scientists, analytical chemists, geospatial and remote sensing scientists, practitioners, international trade and supply chain specialists, and field experts who conduct reference sample expeditions to bring novel data science approaches to analyzing a range of geospatial and remotely sensed datasets.
Patrick Butler, senior research associate, and Brian Mayer, research associate at the Sanghani Center will be part of the Virginia Tech team.
Key foci of this project include machine learning methods for SIRA analytics; location determination from isotopic ratios; and active sampling strategies to close the loop. Foundational machine learning contributions in science-guided machine learning, contrastive and generative learning paradigms, and active sampling algorithms will support not only the specific domain of SIRA but other adjacent domains in environmental conservation, agricultural forecasting, and smart farm modeling.
“For example, what welearn from our research could be directly applicable to tracing many other illicitly-sourced products and product inputs, including forest risk commodities such as cocoa, soy, and beef,” said L. Monika Moskal, professor at the University of Washington.
The study will have broad and far-reaching impacts on American security and prosperity, as well.
“Many key U.S. adversaries rely on illegal logging to finance their activities,” said Jade Saunders, executive director at World Forest ID. “Detecting and curbing such activities will moderate sources of regional instability and threats to U.S. interests.”
The project will lead to improving geospatial prediction accuracy of product origin and will enable a cost-benefit analysis to minimize future data collection costs and optimize prediction gain. Finally, this project will also positively affect U.S. economic competitiveness by reducing competition with illicit actors and moderating risks to international trade, Ramakrishnan said.
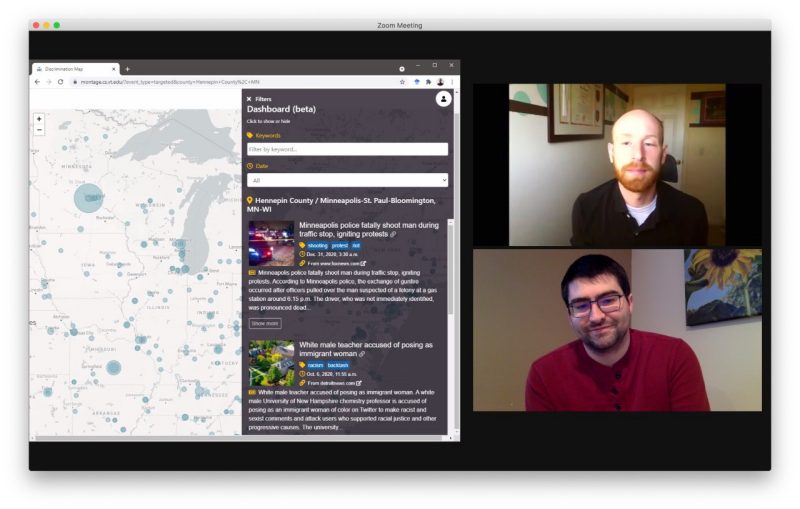
Research associates Brian Mayer (top) and Nathan Self (bottom) meet virtually to review targeted violence events on the dashboard developed by the Sanghani Center.
About the series: Every complex problem has many multidisciplinary angles. Leveraging expertise and energy, Virginia Tech faculty and students serve humanity by addressing the world’s most difficult problems.
With risk of political and targeted violence on the rise across the United States, national and local leaders are asking Princeton University’s nonpartisan Bridging Divides Initiative (BDI) to provide them with more timely, reliable, and context-specific data on targeted violence events that could help them engage locally and better inform their policy decisions.
As part of their response to this plea, BDI’s team of Princeton social scientists collaborated with data scientists at the Sanghani Center for Artificial Intelligence and Data Analytics to identify targeted violence events. These often include hate crimes and other incidents that target individuals because of their race, religion, sexual orientation, or other perceived characteristics. Click here to read more about this research.
Naren Ramakrishnan, Director of DAC and Professor in the Department of Computer Science
The Discovery Analytics Center has received a research award from the Center for Security and Emerging Technology (CSET) at Georgetown University to support data-informed analysis for policymakers concerning emerging technologies and their security implications. DAC will develop methods to extract novel insights at scale from full-text analytics of publications to better understand emerging technologies and their prevalence, spatial and temporal trends, and relationships.
“Algorithmic components developed by DAC will go into a high-performance pipeline that enables inspection of extracted patterns as well as the lineage of data transformations underlying the patterns,” said Naren Ramakrishnan, the Thomas L. Phillips Professor of Engineering and DAC director, who is the principal investigator for the project.
Ramakrishnan’s team at DAC — which includes senior research associate Patrick Butler; research associate Brian Mayer; and three Ph.D. students — will develop a machine learning framework based on weak supervision to process full-text AI publications into extracted structured fields, such as information on computational platforms utilized, language and library dependencies, compute time, research methods, objective tasks, and links to source code and data resources.
The initial focus will be on arXiv as researchers evaluate and assess progress followed by extraction from China National Knowledge Infrastructure (CNKI) literature, which provides full-text articles from more than 8,000 Chinese journals covering natural sciences, engineering, technology, agriculture, medicine, and selected topics in economics and social sciences.
This project is providing DAC with the opportunity to build on its prior work in extracting information from news articles about civil unrest events. It will also be informed by DAC’s experience with automated extraction of epidemiological line lists from disease reports, which is used to develop custom word embeddings aimed at recognizing the typical language patterns in how computational details are described in the scholarly literature.
“This project brings together machine learning, computational linguistics, and human-computer interaction capabilities to extract features at scale. The information we extract will be mapped over time to help identify key trends and potential gaps that can support analysts and policy makers at the CSET,” said Ramakrishnan.
“We are looking forward to seeing how this innovative work can help inform CSET’s analysis as we strive to inform the future of AI policy,” said Dewey Murdick, director of Data Science at CSET.
The overall theme of this year’s conference is data mining for social good.
Chandan Reddy, associate professor of computer science and DAC faculty, served as a poster co-chair for the KDD conference.
Naren Ramakrishnan, the Thomas L. Phillips Professor of Engineering and DAC director, served on the senior program committee for the KDD research track.
This workshop serves as a forum to discuss new insights into how data mining can play a bigger role in epidemiology and public health research. While the integration of data science methods into epidemiology has significant potential, it remains understudied, Prakash said.
The goal of the workshop is to raise the profile of this emerging research area of data-driven and computational epidemiology and create a venue for presenting state-of-the-art and in-progress results — in particular, results that would otherwise be difficult to present at a major data mining conference, including lessons learned in the “trenches.”
An Urban Computing workshop is also scheduled in conjunction with KDD2018. The objective of this workshop is to provide professionals, researchers, and technologists with a single forum where they can discuss and share the state-of-the-art of the development and applications related to urban computing, present their ideas and contributions, and set future directions in innovative research for urban computing. It is particularly targeted to people who are interested in sensing/mining/understanding urban data so as to tackle challenges in cities and help better formulate the future of cities.
The following posters from DAC have been accepted for presentation at the workshop:
“Privacy Preserving Smart Meter Data” (Swapna Thorve, Lindah Kotut, and Mary Semaan). Thorve and Kotut are NSF research trainees in the UrbComp program.